ss::future<>f(){std::cout<<"run on shard-"<<ss::this_shard_id()<<std::endl;returnss::smp::submit_to(1,[](){std::cout<<"run on shard-"<<ss::this_shard_id()<<std::endl;});}
首先在当前 shard 打印其 id,然后往 id 为 1 的 shard 提交一个异步任务,该异步任务也只是简单地打印出所在 shard 的 id
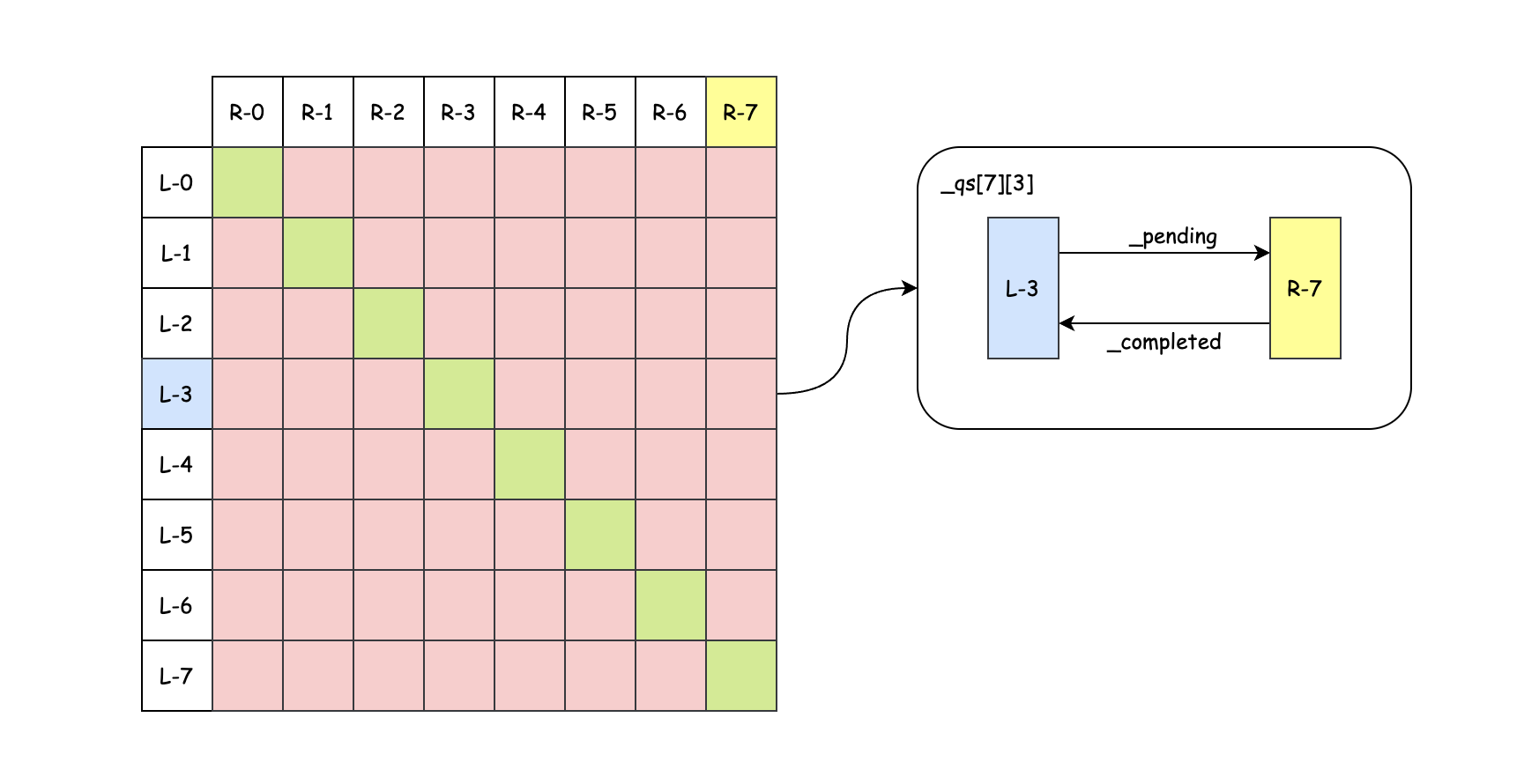
classsmp_message_queue{staticconstexprsize_tqueue_length=128;staticconstexprsize_tbatch_size=16;staticconstexprsize_tprefetch_cnt=2;structwork_item;structlf_queue_remote{reactor*remote;};usinglf_queue_base=boost::lockfree::spsc_queue<work_item*,boost::lockfree::capacity<queue_length>>;// use inheritence to control placement order
structlf_queue:lf_queue_remote,lf_queue_base{lf_queue(reactor*remote):lf_queue_remote{remote}{}voidmaybe_wakeup();~lf_queue();};lf_queue_pending;lf_queue_completed;uniontx_side{tx_side(){}~tx_side(){}voidinit(){new(&a)aa;}structaa{std::deque<work_item*>pending_fifo;}a;}_tx;std::vector<work_item*>_completed_fifo;}
structwork_item:publictask{explicitwork_item(smp_service_groupssg):task(current_scheduling_group()),ssg(ssg){}smp_service_groupssg;virtual~work_item(){}virtualvoidfail_with(std::exception_ptr)=0;voidprocess();virtualvoidcomplete()=0;};template<typenameFunc>structasync_work_item:work_item{smp_message_queue&_queue;Func_func;usingfuturator=futurize<std::invoke_result_t<Func>>;usingfuture_type=typenamefuturator::type;usingvalue_type=typenamefuture_type::value_type;std::optional<value_type>_result;std::exception_ptr_ex;// if !_result
typenamefuturator::promise_type_promise;// used on local side
async_work_item(smp_message_queue&queue,smp_service_groupssg,Func&&func):work_item(ssg),_queue(queue),_func(std::move(func)){}};
voidsmp_message_queue::submit_item(shard_idt,smp_timeout_clock::time_pointtimeout,std::unique_ptr<smp_message_queue::work_item>item){// matching signal() in process_completions()
autossg_id=internal::smp_service_group_id(item->ssg);auto&sem=get_smp_service_groups_semaphore(ssg_id,t);// Future indirectly forwarded to `item`.
(void)get_units(sem,1,timeout).then_wrapped([this,item=std::move(item)](future<smp_service_group_semaphore_units>units_fut)mutable{if(units_fut.failed()){return;}_tx.a.pending_fifo.push_back(item.get());// no exceptions from this point
item.release();units_fut.get0().release();if(_tx.a.pending_fifo.size()>=batch_size){move_pending();}});}voidsmp_message_queue::move_pending(){autobegin=_tx.a.pending_fifo.cbegin();autoend=_tx.a.pending_fifo.cend();end=_pending.push(begin,end);if(begin==end){return;}autonr=end-begin;_pending.maybe_wakeup();_tx.a.pending_fifo.erase(begin,end);_current_queue_length+=nr;_last_snt_batch=nr;_sent+=nr;}
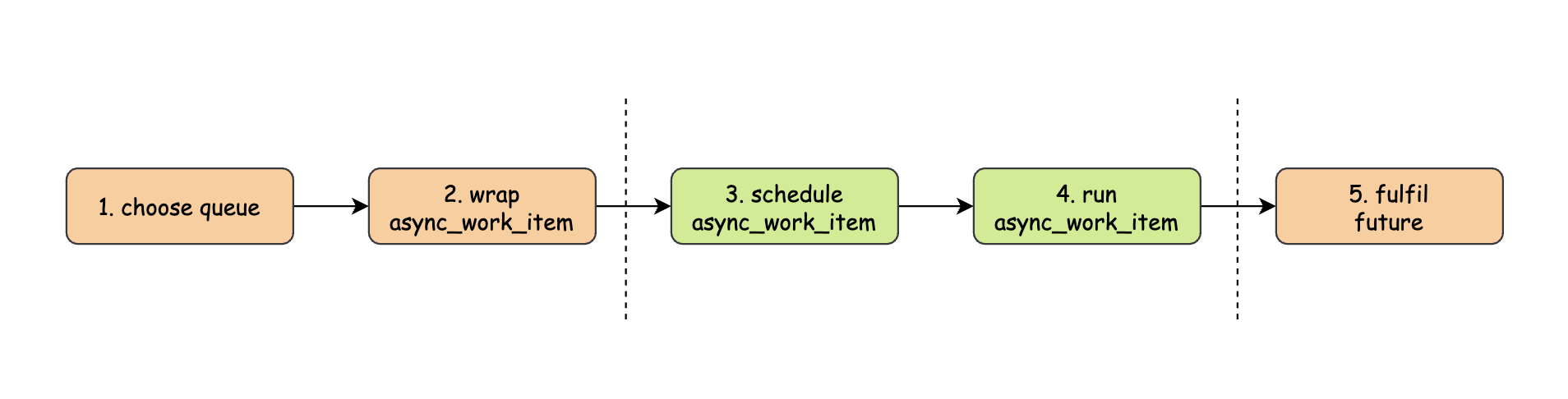
An async submit_to round trip: local shard sends work out, remote shard executes it, then the completion chain returns home
两边橙色矩形内的工作属于 local shard,中间绿色矩形中的工作属于 remote shard。需要注意最后一步:之前在本地线程执行本地任务时,我们都是直接在 task::run_and_dispose 中 fulfil future,但是在异步任务中我们不能这样,因为此时 promise 在 remote shard,future 在 local shard,而二者需要操纵同一块数据(future_state,promise 写,future 读),而 Seastar 中的 FPC 是没有加锁的,那么在异步任务场景下势必会出问题,所以我们需要将 promise 送回 local shard,让它和 future 在同一个线程上执行:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
virtualvoidrun_and_dispose()noexceptoverride{// _queue.respond() below forwards the continuation chain back to the
// calling shard.
(void)futurator::invoke(this->_func).then_wrapped([this](autof){if(f.failed()){_ex=f.get_exception();}else{_result=f.get();}_queue.respond(this);});// We don't delete the task here as the creator of the work item will
// delete it on the origin shard.
}
virtualvoidcomplete()override{if(_result){_promise.set_value(std::move(*_result));}else{// FIXME: _ex was allocated on another cpu
_promise.set_exception(std::move(_ex));}}