Seastar: temporary buffer
Preface
temporary_buffer 是 Seastar 提供的一种自我管理(self-managed)字节缓冲区,它类似于 std::string 或者 std::unique_ptr<char[]>,但是提供了一些更加灵活的内存管理机制,比如它可以独占底层的缓冲区,也可以和其他 temporary_buffer 共享底层缓冲区、甚至只共享其他 temporay_buffer 底层缓冲区的一部分…,因为这些功能,这个数据结构在 Seastar 以及 Scylla/RedPanda 等基于 Seastar 的项目中使用得非常广泛
temporary buffer
首先来看看其结构定义:
|
|
非常简单的一个结构,其中 _buffer 就是其底层缓冲区,_size 就是该缓冲区的大小;但是需要注意的是,由于 temporay_buffer 是可以从其他 temporary_buffer 共享的(甚至只共享一部分),所以 _buffer 可能并是最初分配的内存的起始地址,因此 _size 也可能并不是最初分配内存的大小
二者的关系可能是这样:
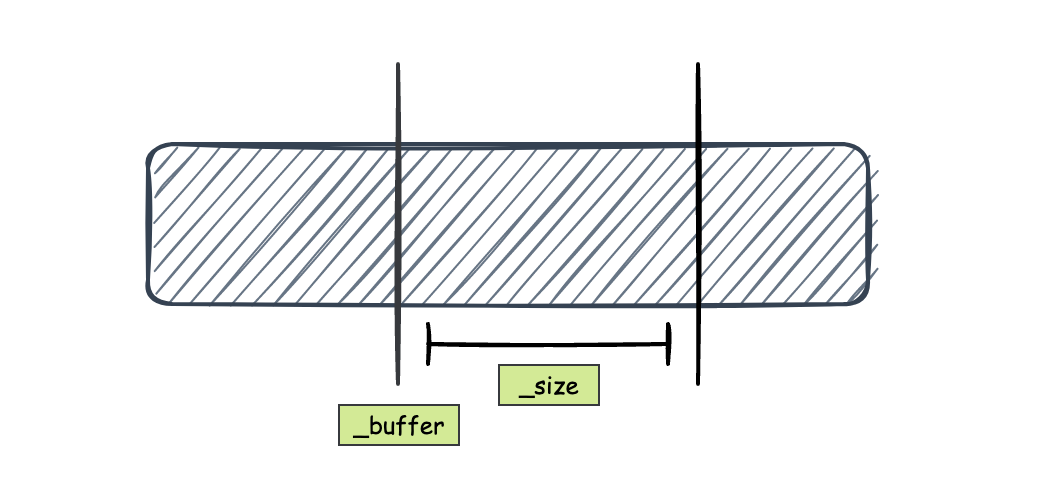
而 deleter 自然就是用来释放该内存的工具了,相关逻辑暂且按下不表,后面会用另外一个 section 来解读,还是很有趣的
构造 & 析构
首先来看看它的构造和析构函数:
|
|
一个是默认构造函数,另一个则是指定缓冲区的大小,然后用 malloc 分配指定大小的缓冲区,此时 deleter 通过 make_free_deleter 构造出来,它的功能和它的名字一样:通过 std::free 释放 _buffer;还有一个则是直接传入 raw buffer 和 size,以及自定义deleter
此外它还提供了移动构造函数/移动赋值,但是不支持拷贝构造/拷贝赋值——他们是删除的(=delete)
temporary_buffer 并没有显式提供析构函数,所以他们是编译期生成的默认版本——所以可以想象的出来,deleter 会在其析构时释放 _buffer 的内存空间
常用操作
temporary_buffer 提供了一些常见的类 STL 容器的操作,比如 operator[]、size()、empty() 以及 begin() 和 end() 操作,除此之外还有一些特有的操作:
get_write()
|
|
前面提到的场景操作基本都是将 temporary_buffer 看作一个只读的数据结构来实现的——比如 begin() 和 end() 返回的都是 const CharType *,operator[] 返回的是 CharType 而不是 CharType &;这是因为 temporary_buffer 是支持共享的,也就是说一个这样的数据结构可能有多个 user 在使用着,所以如果不是非常确定,最好不要改动里面的数据,否则可能造成不可预料的后果
而 get_write() 则是以 CharType * 返回底层缓冲区,也就是说可以通过它往底层缓冲区里面写数据——这也是大多数网络 I/O 所使用的方法(除此之外还有 net::packet ,不过这个过于底层一般也用不着)
trim()、trim_front()
|
|
“修剪” 操作,trim 是移除 suffix,trim_front 是移除 prefix;不过二者的 pos 参数意义不同,trim 中的 pos 参数并不指明需要移除的 suffix 的长度,而是说移除 suffix 之后剩余的长度(或许改名叫 trim_to 更好?);trim_front 中的 pos 则是实打实的指明需要移除的 prefix 的长度
这俩方法也说明,_buffer 并不就是初始分配的缓冲区,而是有可能只是它的一部分
share()
|
|
重头戏来了,这是我觉得 temporary_buffer 相比于 std::string、std::unique_ptr<char[]> 最有价值的一个功能
经常有这种场景,对于一块数据,我们需要从其中拿出一部分来处理,协议处理中常见的 header 处理;如果用 std::string,我们或许可以通过 substr 拿出一个子串,不过这存在着拷贝,效率太低;或者通过 std::string_view 引用原始 std::string 的一部分,不过这样的话二者之间其实并没有建立联系,所以倘若 std::string 被释放那么再使用这个 std::string_view 就会出问题——所以我们需要将 std::string 保持直到 std::string_view 不再被使用——但是在异步场景下做到这一点也很难,至少不那么直观,或者不那么自动化
temporary_buffer() 则在不同的 share 之间建立了联系——通过传统的 RAII,外加引用计数——从而优雅地解决了这个问题——无需使用者关心何时释放原始字符串;不过这一点也留在 deleter 这个 section 去探究
为什么 temporary
一开始我看到这个数据结构时,我就在想,为什么它要叫 temporary_buffer 呢,改叫 bytes_buffer 不行么?代码中的注释给我们做了解答:
A temporary_buffer should not be held indefinitely. It can be held while a request is processed, or for a similar duration, but not longer, as it can tie up more memory that its size indicates.
首先不推荐长时间持有一个 temporary_buffer,它最好只在一个请求的生命周期内使用(或者与之类似的时长),再长就不太好了,这就是它叫做 temporary_buffer 的原因;但是为什么不推荐长时间持有呢?因为它表面看起来的 size 可能并不代表它实际占用的内存——想象 trim 和 share 操作:一个 size() 为 16B 的 temporary_buffer 可能是从另一个 size() 为 1GB 的 temporary_buffer 中共享出来的(所谓冰山一角),而如果我们长时间持有它,那么原始的缓冲区则将无法得到释放,最终造成系统内存使用量过高,而且还难以 debug
deleter
deleter 一开始并不是为 temporary_buffer 设计的,而只是 net::packet 实现 zero copy 功能的一个 utility,不过后面被抽取出来变成了一个通用的内存管理工具
|
|
deleter 用了 pImpl idiom,deleter::impl 的结构也很简单:其中 refs 为引用计数,这是用来解决 share buffer 的问题,还有一个 deleter 类型的 next 字段(注意并不是 deleter::impl 类型),它比较难理解,不过暂时不用管他,后面有了更多的背景知识就可以理解了
构造 & 析构
首先看看其析构函数:
|
|
通过前面的 temporary_buffer 我们已经发现:其内部的 _buffer 指针可能并不是指向初识分配的内存块首字节而是中间的一段,所以我们不能直接 std::free(_buffer),但是 temporary_buffer 中又没有记录下内存块的首地址,所以如果 _deleter 想要知道该释放哪块内存,就必须由它自己去保存这个信息
虽然 deleter 使用了 pImpl idiom,但是其 _impl 指针有多个用途——它可以是指向实际的 implementation 对象,也可是字节缓冲区的首地址;这两种情况如何区分呢?借助 tagged pointer 这个 trick:如果它的最后一位为 1 的话,说明它直接指向的是要释放的内存块首地址,可以直接 std::free() 掉;否则的话它就是一个 implementation pointer,此时需要递减引用计数,当它为 0 时才可以删除 implementation 对象;
implementation object 是用来存储引用计数的,但是在没有调用 share()/trim() 操作时,我们并不需要引用计数,也没有必要一上来就分配一个 implementation object,通过 tagged pointer,我们减少了不必要的内存分配
is_raw_object 就是检查 tag,from_raw_object 和 to_raw_object 分别是在 _impl 中加上/清除 tag:
|
|
在指定长度创建 temporary_buffer 时,其 _deleter 成员通过 make_free_deleter(_buffer) 初始化,里面就调用了 deleter 带 raw_object_tag 的构造函数:
|
|
那么问题来了,什么时候 _impl 才会真正指向其 implementation 对象呢?那时又是在何处保存缓冲区首地址呢(deleter::impl 中似乎没有地方)?这个就是常用操作中的重点了
常用操作:
share()
|
|
这是 deleter 最重要的方法之一,temporary_buffer() 的 share() 方法就是在该方法之上实现的,通过这个方法我们可以看到它是如何在两个共享底层 buffer 的 temporary_buffer 之间建立联系并处理内存释放这个问题的
如果 _impl 指向的是 raw object,那么需要将其转换为一个 deleter::_impl 结构——这样才能记录下引用计数,当然也不完全是 deleter::_impl——因为它里面没有地方可以存储 raw object,所以是它的一个子类 free_deleter_impl:
|
|
其中的 obj 指针就可以用来存储 raw object。然后递增其引用计数,并通过 _impl 构造一个新的 deleter,这样两个 deleter 就共享同一个 _impl,并且其引用计数为 2——每个 deleter 析构时都会递减引用计数,当引用计数递减至 0 时会 delete _impl 从而调用其析构函数,在其析构函数中会真正地释放缓冲区内存
而 deleter 是作为一个 data member 存储在 temporary_buffer 中,所以只要它析构,就会导致 deleter 析构,最终只有在所有 share 副本都析构时,其缓冲区才会真正被释放
append()
|
|
TODO: 现在对这个方法的使用场景和实现原理还不理解,后面看
net::packet时再回过头来看看它吧
总结
temporary_buffer 其实就是一个类似于 std::string 的字节缓冲区,但是相比于 std::string 它最大的特点就是可以和其他的 temporary_buffer 共享底层的字节缓冲区(所有或者只是一部分),而不用使用者去操心该何时去释放这块内存,这一点在异步场景中非常有用——虽然对于 std::string 我们可以搭配 std::string_view 构造出类似的共享底层缓冲区的功能,但是使用起来割裂感就很强
deleter 则是一个通用的内存管理工具,它是 temporary_buffer 实现底层缓冲区共享的关键;其实它的实现也不复杂,其实还是很常见的引用计数,外加一些小技巧来简化实现/减少内存占用