Preface
虽然 Seastar 号称 share-nothing,但是现代服务器开发中仍免不了需要核间通信;Seastar 为此在 smp 类中提供了 submit_to 方法用于向其他线程的 reactor 提交任务并执行:
1
2
|
static futurize_t<std::invoke_result_t<Func>>
submit_to(unsigned t, Func&& func) noexcept;
|
比如下面的代码:
1
2
3
4
5
6
|
ss::future<> f() {
std::cout << "run on shard-" << ss::this_shard_id() << std::endl;
return ss::smp::submit_to(1, []() {
std::cout << "run on shard-" << ss::this_shard_id() << std::endl;
});
}
|
首先在当前 shard 打印其 id,然后往 id 为 1 的 shard 提交一个异步任务,该异步任务也只是简单地打印出所在 shard 的 id
使用 app_template 执行该函数得到结果:
1
2
3
|
% sudo ./my_app -c 2
run on shard-0
run on shard-1
|
的确第二句 std::cout 是在 shard-1 上执行的;这里需要注意由于使用了两个 shard,所以至少需要使用两个核(-c 2)。
源码剖析
这里涉及到两个核之间的通信,所以有必要先规定几个叫法:
- local core/local shard/local reactor:指发起通信的一方
- remote core/remote shard/remote reactor:指接收方
前面提到的 submit_to 函数实际上是以默认的 smp_submit_to_options 参数调用的下面这个函数:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
|
class smp : public std::enable_shared_from_this<smp> {
std::unique_ptr<smp_message_queue*[], qs_deleter> _qs_owner;
static thread_local smp_message_queue**_qs;
public:
template <typename Func>
static futurize_t<std::invoke_result_t<Func>>
submit_to(unsigned t, smp_submit_to_options options, Func&& func) noexcept
{
using ret_type = std::invoke_result_t<Func>;
if (t == this_shard_id()) {
...
} else {
return _qs[t][this_shard_id()].submit(t, options, std::forward<Func>(func));
}
}
};
|
submit_to 函数既可以向 remote shard 提交任务,也可以向 local shard 提交任务,但是我们现在只专注于前者。
异步任务队列
Seastar 中使用了无锁队列来实现跨核通信。要达到无锁,就不能出现多读多写,所以这里任意两个 shard 之间都需要一个队列,对于 8C 的 CPU,就需要 $8 * (8 - 1)$个队列(自己无需跟自己通讯);smp 中的 smp_message_queue 的二维数组就承担着这个角色:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
|
class smp_message_queue {
static constexpr size_t queue_length = 128;
static constexpr size_t batch_size = 16;
static constexpr size_t prefetch_cnt = 2;
struct work_item;
struct lf_queue_remote {
reactor* remote;
};
using lf_queue_base = boost::lockfree::spsc_queue<work_item*,
boost::lockfree::capacity<queue_length>>;
// use inheritence to control placement order
struct lf_queue : lf_queue_remote, lf_queue_base {
lf_queue(reactor* remote) : lf_queue_remote{remote} {}
void maybe_wakeup();
~lf_queue();
};
lf_queue _pending;
lf_queue _completed;
union tx_side {
tx_side() {}
~tx_side() {}
void init() { new (&a) aa; }
struct aa {
std::deque<work_item*> pending_fifo;
} a;
} _tx;
std::vector<work_item*> _completed_fifo;
}
|
可以看到里面有两个 capacity 为 128 的 SPSC(Single Producer Single Consumer)无锁环形队列,其中 _pending 用于存储等待执行的异步任务,_completed 用于存储已经执行完毕的异步任务(即提交队列与完成队列);每个队列都记住着与之通信的 remote reactor。
初始化任务队列
所有 shard 的任务队列都在在 shard-0 中被创建:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
|
void smp::configure(const smp_options& smp_opts, const reactor_options& reactor_opts)
{
_qs_owner = decltype(smp::_qs_owner){new smp_message_queue* [smp::count], qs_deleter{}};
_qs = _qs_owner.get();
for(unsigned i = 0; i < smp::count; i++) {
smp::_qs_owner[i] = reinterpret_cast<smp_message_queue*>(operator new[] (sizeof(smp_message_queue) * smp::count));
for (unsigned j = 0; j < smp::count; ++j) {
new (&smp::_qs_owner[i][j]) smp_message_queue(reactors[j], reactors[i]);
}
}
smp_queues_constructed.wait();
start_all_queues();
}
smp_message_queue::smp_message_queue(reactor* from, reactor* to)
: _pending(to)
, _completed(from) { }
|
最终得到的是一个任务队列的矩阵(二级指针):
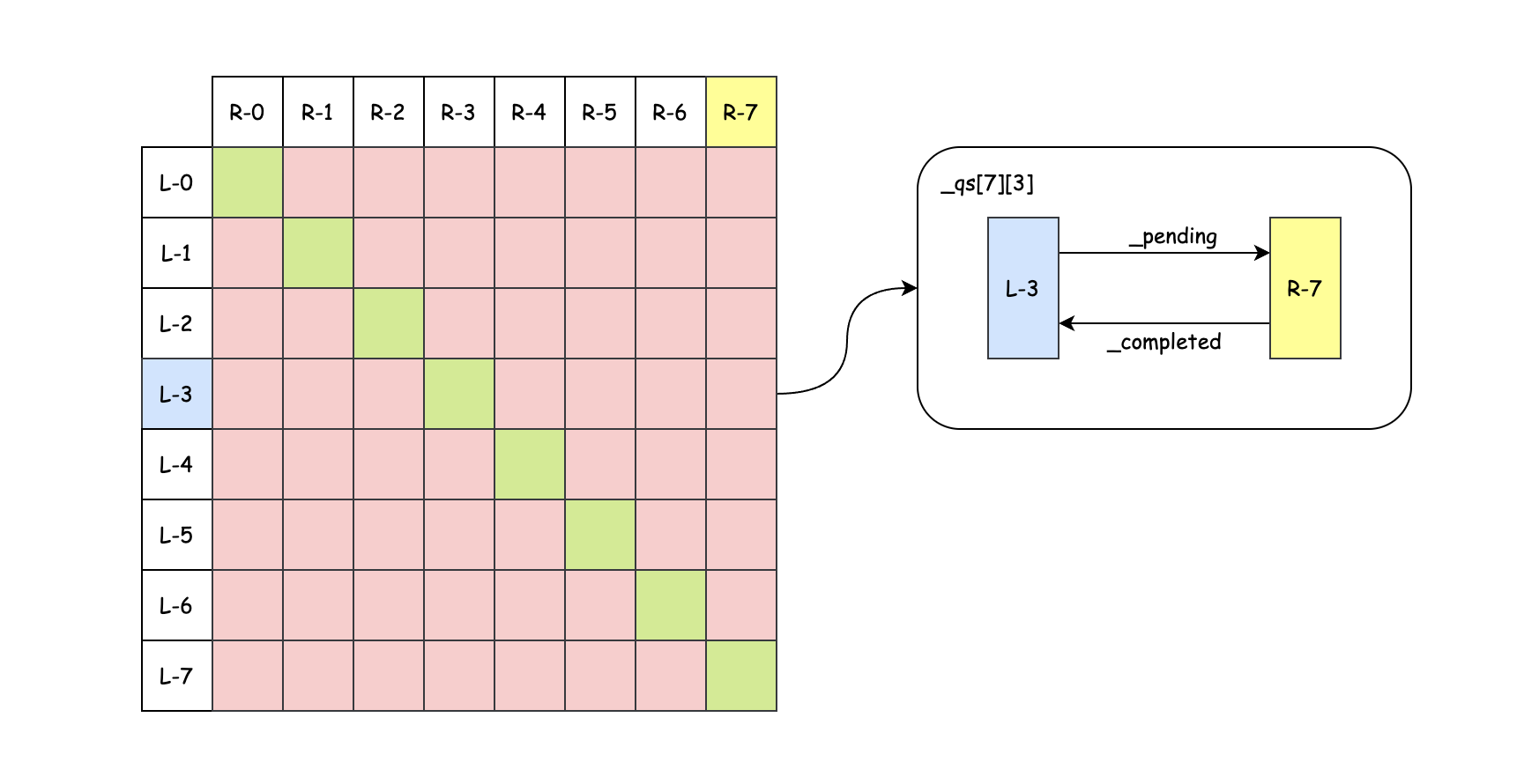
- 矩阵的一维下标为 remote shard 的 shard id,二维下标为 local shard 的 shard id(TODO: 为啥要这样,感觉有点不自然);处于对角线上的元素(绿色方格)实际上并没有用到(自己无需与自己通信)
- local shard 向 remote shard 提交一个异步任务,需要用到两个队列,其中
_pending 用来发送任务,_completed 用来接收结果;也就是对于 _pending 队列,remote 为 remote shard;对于 _completed 队列,remote 则为 local shard;总而言之,local/remote 是一个相对的概念
- 虽然
_pending 队列和 _completed 队列的元素类型是相同的,但是异步任务的返回值不能投递到 local shard 的 _pending 队列(比如 L-3 往 R-7 通过 _qs[7][3]._pending 提交任务,然后响应则通过 _qs[3][7].pending 返回给 L-3);因为 _pending 是请求,而 _completed 是响应,二者有着不同的处理逻辑
在其他 reactor 中则直接共享该二级指针:
1
2
3
4
5
6
7
8
9
10
|
void smp::configure(const smp_options& smp_opts, const reactor_options& reactor_opts)
{
auto smp_tmain = smp::_tmain;
for (i = 1; i < smp::count; i++) {
create_thread([this, smp_tmain, inited, &smp_queues_constructed...] {
smp_queues_constructed.wait();
_qs = _qs_owner.get();
});
}
}
|
提交异步任务
异步任务的提交其实就是将其放入 smp_message_queue 的队列:
1
2
3
4
5
6
7
8
9
10
|
template <typename Func>
futurize_t<std::invoke_result_t<Func>>
smp_message_queue::submit(shard_id t, smp_submit_to_options options, Func&& func) noexcept
{
memory::scoped_critical_alloc_section _;
auto wi = std::make_unique<async_work_item<Func>>(*this, options.service_group, std::forward<Func>(func));
auto fut = wi->get_future();
submit_item(t, options.timeout, std::move(wi));
return fut;
}
|
里面首先将要执行的函数包裹成一个 async_work_item,这是 work_item 的一个子类:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
|
struct work_item : public task {
explicit work_item(smp_service_group ssg) : task(current_scheduling_group()), ssg(ssg) {}
smp_service_group ssg;
virtual ~work_item() {}
virtual void fail_with(std::exception_ptr) = 0;
void process();
virtual void complete() = 0;
};
template<typename Func>
struct async_work_item : work_item {
smp_message_queue& _queue;
Func _func;
using futurator = futurize<std::invoke_result_t<Func>>;
using future_type = typename futurator::type;
using value_type = typename future_type::value_type;
std::optional<value_type> _result;
std::exception_ptr _ex; // if !_result
typename futurator::promise_type _promise; // used on local side
async_work_item(smp_message_queue& queue, smp_service_group ssg, Func&& func) : work_item(ssg), _queue(queue), _func(std::move(func)) {}
};
|
在 async_work_item 中保存了要执行的函数,以及发起本次异步任务提交的 smp_message_queue——之后还得将结果送回去。由于这是一个异步操作,所以 smp::submit_to 的返回值必然是一个 future,所以在 async_work_item 中还保存了该 future 关联的 promise——以便在异步操作完成后激活该 future。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
|
void smp_message_queue::submit_item(shard_id t, smp_timeout_clock::time_point timeout, std::unique_ptr<smp_message_queue::work_item> item) {
// matching signal() in process_completions()
auto ssg_id = internal::smp_service_group_id(item->ssg);
auto& sem = get_smp_service_groups_semaphore(ssg_id, t);
// Future indirectly forwarded to `item`.
(void)get_units(sem, 1, timeout).then_wrapped([this, item = std::move(item)] (future<smp_service_group_semaphore_units> units_fut) mutable {
if (units_fut.failed()) {
return;
}
_tx.a.pending_fifo.push_back(item.get());
// no exceptions from this point
item.release();
units_fut.get0().release();
if (_tx.a.pending_fifo.size() >= batch_size) {
move_pending();
}
});
}
void smp_message_queue::move_pending() {
auto begin = _tx.a.pending_fifo.cbegin();
auto end = _tx.a.pending_fifo.cend();
end = _pending.push(begin, end);
if (begin == end) {
return;
}
auto nr = end - begin;
_pending.maybe_wakeup();
_tx.a.pending_fifo.erase(begin, end);
_current_queue_length += nr;
_last_snt_batch = nr;
_sent += nr;
}
|
可以将整个操作分为两步:
- 首先将
async_work_item 放入 smp_message_queue::_tx::a::pending_fifo 这个先进先出队列
- 当该队列中的 item 积攒到一定个数(
smp_message_queue::batch_size),会将 FIFO 中的所有 item 移入 smp::message_queue::_pending 队列
TODO: 之所以需要这样,我觉得主要还是考虑到
此外,还有几点值得注意:
- 在第一步将
async_work_item 放入 FIFO 时,还使用了 semphore 控制异步任务的执行速率。
- 在第二步中执行了
_pending.maybe_wakeup() 主要是考虑到如果 remote core 进入了休眠模式,则需要将其唤醒
处理异步任务
每个 reactor 都注册了一个 smp poller,专门用于处理异步任务相关的工作:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
|
class reactor::smp_pollfn final : public reactor::pollfn {
reactor& _r;
public:
smp_pollfn(reactor& r) : _r(r) {}
virtual bool poll() final override {
return (smp::poll_queues() |
_r._alien.poll_queues());
}
};
bool smp::poll_queues() {
size_t got = 0;
for (unsigned i = 0; i < count; i++) {
if (this_shard_id() != i) {
auto& rxq = _qs[this_shard_id()][i];
rxq.flush_response_batch();
got += rxq.has_unflushed_responses();
got += rxq.process_incoming();
auto& txq = _qs[i][this_shard_id()];
txq.flush_request_batch();
got += txq.process_completions(i);
}
}
return got != 0;
}
size_t smp_message_queue::process_incoming() {
auto nr = process_queue<prefetch_cnt>(_pending, [] (work_item* wi) {
wi->process();
});
_received += nr;
_last_rcv_batch = nr;
return nr;
}
|
逻辑很简单,就是从所有其他 shard 提交到当前 shard 的队列(_qs[this_shard_id()][i])取出任务并执行其 process 方法,对于 async_work_item,就是继承的 work_item 的 process 方法:
1
2
3
|
void smp_message_queue::work_item::process() {
schedule(this);
}
|
即将该 async_work_item(task的一个子类)放入当前 reactor 的本地任务队列中,当成一个本地任务执行。
异步任务返回
然而虽然异步任务是模拟成本地任务执行,但是它终究不是本地任务,我们先看看在整个异步任务执行过程中,哪些工作属于local shard ,哪些工作属于 remote shard:
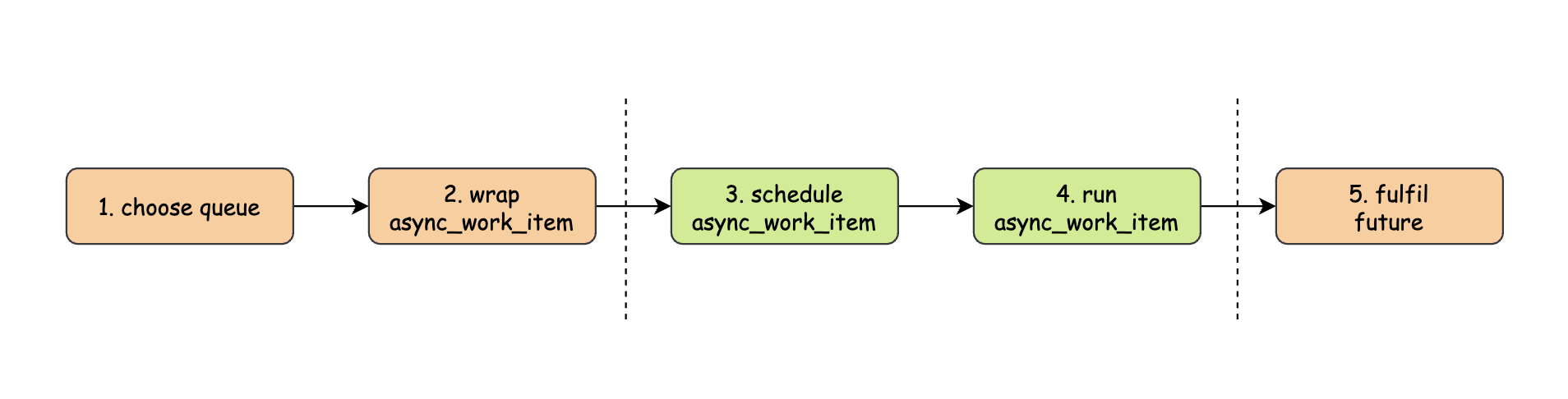
两边橙色矩形内的工作属于 local shard,中间绿色矩形中的工作属于 remote shard。需要注意最后一步:之前在本地线程执行本地任务时,我们都是直接在 task::run_and_dispose 中 fulfil future,但是在异步任务中我们不能这样,因为此时 promise 在 remote shard,future 在 local shard,而二者需要操纵同一块数据(future_state,promise 写,future 读),而 Seastar 中的 FPC 是没有加锁的,那么在异步任务场景下势必会出问题,所以我们需要将 promise 送回 local shard,让它和 future 在同一个线程上执行:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
|
virtual void run_and_dispose() noexcept override {
// _queue.respond() below forwards the continuation chain back to the
// calling shard.
(void)futurator::invoke(this->_func).then_wrapped([this] (auto f) {
if (f.failed()) {
_ex = f.get_exception();
} else {
_result = f.get();
}
_queue.respond(this);
});
// We don't delete the task here as the creator of the work item will
// delete it on the origin shard.
}
|
可以看到这里并没有直接 _promise.set_value()/_promise.set_exception(),而是调用了发起该异步任务的 message queue 的 respond 方法,这个方法和 submit_item 类似,也是先将 async_work_item 放入一个 FIFO,等到达一定数目后再全部转移至 _completed 队列中;而 smp poller 除了处理异步任务请求之外,还会处理异步任务结果(逻辑也在 smp::poll_queues):
1
2
3
4
5
6
7
8
9
10
11
12
13
|
size_t smp_message_queue::process_completions(shard_id t) {
auto nr = process_queue<prefetch_cnt*2>(_completed, [t] (work_item* wi) {
wi->complete();
auto ssg_id = smp_service_group_id(wi->ssg);
get_smp_service_groups_semaphore(ssg_id, t).signal();
delete wi;
});
_current_queue_length -= nr;
_compl += nr;
_last_cmpl_batch = nr;
return nr;
}
|
最终调用的是 async_work_item 的 complete 方法:
1
2
3
4
5
6
7
8
|
virtual void complete() override {
if (_result) {
_promise.set_value(std::move(*_result));
} else {
// FIXME: _ex was allocated on another cpu
_promise.set_exception(std::move(_ex));
}
}
|
所以最终 fulfil/resolve future 的操作是在这里——和 future 相同的线程上完成的,这也是 async_work_item 中要保存异步任务执行的结果以及产生的异常的原因。
一些 utility
在 smp::submit_to 的基础上,Seastar 还在 seastar::smp 下提供了两个有用的 utility:
invoke_on_all
1
2
3
4
5
6
7
8
9
10
11
12
13
14
|
template<typename Func>
static future<> invoke_on_all(Func&& func) noexcept {
return invoke_on_all(smp_submit_to_options{}, std::forward<Func>(func));
}
template<typename Func>
SEASTAR_CONCEPT( requires std::is_nothrow_move_constructible_v<Func> )
static future<> invoke_on_all(smp_submit_to_options options, Func&& func) noexcept {
static_assert(std::is_same<future<>, typename futurize<std::invoke_result_t<Func>>::type>::value, "bad Func signature");
static_assert(std::is_nothrow_move_constructible_v<Func>);
return parallel_for_each(all_cpus(), [options, &func] (unsigned id) {
return smp::submit_to(id, options, Func(func));
});
}
|
从名字也可以看出来,就是在所有 shard 上执行一个任务;当所有异步任务都完成之后返回的 future<> 才会被 resolve
invoke_on_others
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
|
template<typename Func>
SEASTAR_CONCEPT( requires std::is_nothrow_move_constructible_v<Func> )
static future<> invoke_on_others(unsigned cpu_id, Func func) noexcept {
return invoke_on_others(cpu_id, smp_submit_to_options{}, std::move(func));
}
template<typename Func>
SEASTAR_CONCEPT( requires std::is_nothrow_move_constructible_v<Func> &&
std::is_nothrow_copy_constructible_v<Func> )
static future<> invoke_on_others(unsigned cpu_id, smp_submit_to_options options, Func func) noexcept {
static_assert(std::is_same<future<>, typename futurize<std::invoke_result_t<Func>>::type>::value, "bad Func signature");
static_assert(std::is_nothrow_move_constructible_v<Func>);
return parallel_for_each(all_cpus(), [cpu_id, options, func = std::move(func)] (unsigned id) {
return id != cpu_id ? smp::submit_to(id, options, Func(func)) : make_ready_future<>();
});
}
|
类似的,就是在当前 shard 之外的所有 shard 上执行一个任务;当所有异步任务都完成之后该函数返回的 future<> 才会被 resolve
总结
Seastar 并没有使用共享内存来实现不同核之间的通信,而是采用了 message-passing 的方式,这也是它的 share-nothing design 的一大体现;这不由得让我想起来 GoLang 最著名的一句格言:
Don’t communicate by sharing memory, share memory by communicating.
Seastar 的高性能再一次印证了这句话的正确性
Reference