2022-03-26
循环是绝大多数编程语言中必不可少的控制结构,比如 C++ 对数组中的元素求和:
int sum(const std::vector<int> &ints) {
int res = 0;
for (size_t i = 0; i < ints.size(); i++) {
res += ints[i];
}
return res;
}然而在 Seastar
中,写循环却不是一件容易的事情——当然不是上面这种不涉及到任何的异步操作的循环,而是指循环重复执行一个异步操作。比如我们想实现这样一个
search 函数:它依次从 Google、Bing 和 Baidu
搜索,有一个成功则将其内容输出至标准输出并停止搜索;或许我们可以马上写出下面这样一段代码:
extern ss::future<std::string> fetch(const std::string &domain,
const std::string &object);
void search(const std::string &object) {
static std::vector<std::string> domains = {
"www.google.com",
"www.bing.com",
"www.baidu.com",
};
for (size_t i = 0; i < domains.size(); i++) {
auto fut = fetch(domains[i]);
if (!fut.is_failed()) {
std::cout << fut.get0() << std::endl;
return;
}
}
}然而 fetch
函数是一个异步操作,也就是说,这个函数不会阻塞,而是立即返回;而它返回的
future 很大程度上不是 ready
的,所以我们无法判断其状态,除非我们等待,然而这就失去了异步的意义(而且
Seastar 不允许我们在非 seastar::thread 环境中等待一个
future)。
再退一步,就算我们不考虑「有一个成功则返回」这个逻辑,而只是「依次向 Google、Bing 和 Baidu 发起请求」,我们也做不到:
for (size_t i = 0; i < domains.size(); i++) {
(void) fetch(domains[i]).then_wrapped([](ss::future<std::string> &&fut) {
if (fut.failed()) {
std::cout << "fetch FAILED: " << fut.get_exception() << std::endl;
} else {
std::cout << "fetch SUCCEEDED: " << fut.get0() << std::endl;
}
});
}还是之前的原因,fetch
是一个异步操作不会阻塞而是直接返回,所以这里无法保证「在前一个操作完成之后再进行下一个」这个逻辑。
因为这些原因,我们很难直接写出循环,不过还好 Seastar 基于 FPC 提供了许多循环的 utility 供我们使用。
repeat通过名字我们就能理解它的语义「重复执行某个操作,直到某个条件被满足」;函数签名如下:
template<typename AsyncAction>
SEASTAR_CONCEPT( requires seastar::InvokeReturns<AsyncAction, stop_iteration> || seastar::InvokeReturns<AsyncAction, future<stop_iteration>> )
inline
future<> repeat(AsyncAction&& action) noexcept;其中 action 是要执行的异步操作,是一个 callable
object,它需要满足一定的函数签名:
stop_iteration 或者
future<stop_iterator> 类型template<typename Tag>
class bool_class {
bool _value;
public:
static const bool_class yes;
static const bool_class no;
};
struct stop_iteration_tag { };
using stop_iteration = bool_class<stop_iteration_tag>;通过 action 的返回值告知 repeat
函数是否应该继续执行该操作;比如之前的 search 函数用
repeat 的话可以这样改写:
void search(std::string &&object) {
static std::vector<std::string> domains = { ... };
int cur = 0;
(void) ss::do_with(cur, [object = std::move(object)](int &cur) mutable {
return ss::repeat([&cur, object = std::move(object)](){
return fetch(domains[cur], object).then_wrapped([&cur](ss::future<std::string> &&fut) mutable {
if (!fut.failed()) {
std::cout << fut.get0() << std::endl;
return ss::stop_iteration::yes;
}
cur++;
return cur == domains.size() ? ss::stop_iteration::yes
: ss::stop_iteration::no;
});
});
});
}整体逻辑还是比较清晰,有一个点需要注意,这里我们需要在不同的异步操作之间记录下该当前正在重复的次(即
for 循环示例中的下标值)用以从 domains
数组中取出对应的元素,以及判断是否已经遍历了所有域名从而跳出循环,所以使用
do_with 来为我们保存该状态。
repeat_until_value现在对我们的 search
做一些变化:不直接将从搜索引擎得到的结果输出至标准输出,而是将其返回给调用方,也就是说,此时
search 函数需要返回一个
future<std::string>;如果用之前的
repeat,因为 repeat 函数固定返回一个
ss::future<>,无法通过它返回数据,所以只能往
action 中传递一个 out argument 将数据给「带出来」:
ss::future<std::string> search(std::string &&object) {
static std::vector<std::string> domains = { ... };
auto result = ss::make_shared<std::string>();
return ss::do_with(int(), [result, object = std::move(object)](int &cur) mutable {
return ss::repeat([&cur, result, object = std::move(object)](){
return fetch(domains[cur], object).then_wrapped([&cur, result](ss::future<std::string> &&fut) mutable {
std::cout << "fetch from the " << cur << "-th domain: " << domains[cur];
if (!fut.failed()) {
*result = fut.get0();
return ss::stop_iteration::yes;
}
cur++;
std::cout << " FAILED: " << fut.get_exception() << std::endl;
return cur == domains.size() ? ss::stop_iteration::yes
: ss::stop_iteration::no;
});
});
}).then([result]() { return ss::make_ready_future<std::string>(std::move(*result)); });
}由于这些都是异步操作,所以我们不能为 result
分配栈空间,而是分配了一个
ss::shared_ptr<std::string>:内存在堆上,而且可以使用其引用计数自动释放该内存;可以用,但是也很麻烦,还好贴心的
Seastar 又为我们提供了 repeat_until_value 函数:
template<typename AsyncAction>
SEASTAR_CONCEPT( requires requires (AsyncAction aa) {
bool(futurize_invoke(aa).get0());
futurize_invoke(aa).get0().value();
} )
repeat_until_value_return_type<AsyncAction>
repeat_until_value(AsyncAction action) noexcept这个 action 也需要满足一定要求的函数签名:
std::optional<T> 或者
ss::future<std::optional<T>>返回值 repeat_until_value_return_type
还是利用了类型萃取,先不用管具体实现,只需要知道它会把
AsyncAction 返回的 std::optional<T> 或者
ss::future<std::optional<T>> 中的
T 萃取出来并以 ss::future<T>
的形式返回给调用方即可;这是它和 repeat
最大的不同,也正式我们需要的东西。
repeat_until_value 的 AsyncAction 并不像
repeat 一样返回 ss::stop_iteration_tag,那么
repeat_until_value 怎么判断是否需要停止循环呢?关键就在于
std::optional,如果 AsyncAction 返回的是一个
std::optional<T>(),也就是没有值,那么就表示操作还没有完成,应该继续循环,否则的话就停止循环;当然,如果
AsyncAction 返回的是一个 exception
future,肯定也是停止循环。
继续使用 repeat_until_value 修改 search
函数:
ss::future<std::string> search(std::string &&object) {
static std::vector<std::string> domains = { ... };
int cur = 0;
return ss::do_with(cur, [object = std::move(object)](int &cur) mutable { return ss::repeat_until_value([&cur, object = std::move(object)]() {
return fetch(domains[cur], object).then_wrapped([&cur](ss::future<std::string> &&fut) mutable {
if (!fut.failed()) {
return ss::make_ready_future<std::optional<std::string>>(fut.get0());
}
cur++;
return cur == domains.size() ? ss::make_exception_future<std::optional<std::string>>(std::runtime_error("all domain failed"))
: ss::make_ready_future<std::optional<std::string>>(std::nullopt);
});
});
});
};同样的这里使用到了 do_with 来保存循环变量;此外,在所有
domain 都失败的情况下也需要停止循环,但是此时我们不能通过返回一个有值的
std::optional<T>来告知
repeat_until_value 停止循环,所以不能像 repeat
一样只返回一个裸的
std::optional<T>,而是需要将其包裹成
ss::future<std::optional<T>>,通过返回
exception future 来处理这种情况。
do_until对于 repeat
等函数,其循环逻辑和循环是否需要继续的逻辑耦合在一起:
template<typename AsyncAction, typename StopCondition>
SEASTAR_CONCEPT( requires seastar::InvokeReturns<StopCondition, bool> && seastar::InvokeReturns<AsyncAction, future<>> )
inline future<>
do_until(StopCondition stop_cond, AsyncAction action) noexcept;多了一个 StopCondition,这也是一个 callable
object,此时不是通过 AsyncAction 的返回值,而是
StopCondition 的返回值判断是否要继续循环。
用 do_until 改写 repeat 实现的
search 函数:
ss::future<std::string> search(std::string &&object) {
static std::vector<std::string> domains = { ... };
return ss::do_with(int(), bool(), [object = std::move(object)](int &cur, bool &done) {
auto stop_when = [&done] { return done; };
auto do_results = [&cur, &done, object = std::move(object)]() {
return fetch(domains[cur], object).then_wrapped([&cur, &done](ss::future<std::string> &&fut) mutable {
if (!fut.failed()) {
std::cout << " SUCCEEDED: " << fut.get0() << std::endl;
done = true;
return;
}
cur++;
std::cout << " FAILED: " << fut.get_exception() << std::endl;
if (cur == domains.size()) { done = true; }
});
};
return ss::do_until(stop_when, do_results);
}).then([]() { return ss::make_ready_future<std::string>(""); });
}依旧使用 do_with
在异步操作之间记录下当前正在循环的域名下标;此外还多了一个需要记录的
done 标志位,这是一个 AsyncAction 和
StopCondition 共享的状态:AsyncAction
更新该标记,StopCondition 通过该标记告知
do_until 是否要继续循环。
TODO: 什么时候应该使用
do_until?
keep_doing这个函数其实只是 repeat 的一个 wrapper:
template<typename AsyncAction>
SEASTAR_CONCEPT( requires seastar::InvokeReturns<AsyncAction, future<>> )
inline
future<> keep_doing(AsyncAction action) noexcept {
return repeat([action = std::move(action)] () mutable {
return action().then([] {
return stop_iteration::no;
});
});
}很好理解,一直执行一个异步操作,直到它返回一个 exception future
比如我们可以用它写一个 web server:
ss::future<> server() {
ss::listen_options lo;
lo.reuse_address = true;
return ss::do_with(ss::listen(ss::make_ipv4_address({9877}), lo), [](ss::server_socket &listener) {
return ss::keep_doing([&listener]() {
return listener.accept().then_wrapped([](ss::future<ss::accept_result> &&fut) {
if (fut.failed()) {
std::cerr << "accept() failed: " << fut.get_exception() << std::endl;
} else {
auto ar = fut.get0();
std::cout << "accept() from " << ar.remote_address << std::endl;
}
return ss::make_ready_future<>();
});
});
});
}这个 web server 目前只是简单地 accept 一个新的连接并打印 client 的 ip:port,但是稍加扩展我们就可以让它成为一个可用的 HTTP server
do_for_each之前 repeat 的例子中我们是「从 Google、Bing 和 Baidu
依次搜索,输出第一个成功搜索到的内容至标准输出后停止」,倘若我们需要这三个搜索引擎的内容都输出,用
repeat 也可以做到,但是得配合 do_with
使用以保持临时变量(循环计数/下标索引),针对这种「对某个范围内的所有元素依次执行同一个异步操作」的情况,Seastar
为我们提供了 do_for_each 函数,这个函数有两个版本:
template<typename Iterator, typename AsyncAction>
SEASTAR_CONCEPT( requires requires (Iterator i, AsyncAction aa) {
{ futurize_invoke(aa, *i) } -> std::same_as<future<>>;
} )
inline future<>
do_for_each(Iterator begin, Iterator end, AsyncAction action) noexcept;
template<typename Container, typename AsyncAction>
SEASTAR_CONCEPT( requires requires (Container c, AsyncAction aa) {
{ futurize_invoke(aa, *std::begin(c)) } -> std::same_as<future<>>;
std::end(c);
} )
inline future<>
do_for_each(Container& c, AsyncAction action) noexcept;第一个称为 iterator version,第二个称为
range
version,他俩的区别无非是用什么来表示范围,前者使用起止迭代器表示([start,
end)),后者直接使用容器表示。他们都接受一个 AsyncAction
作为最后一个参数,这个 AsyncAction
接受一个范围内元素的引用,并返回一个
future<>;当范围遍历完,或者 AsyncAction
返回了一个 exception future,循环就停止,前者 do_for_each
返回一个正常的 future<>,后者则返回一个 exception
future,以将 AsyncAction 返回的 exception
返回给调用方。
对于前面提到的问题,我们可以用 do_for_each
这样解决:
ss::future<std::string> search(std::string &&object) {
static std::vector<std::string> domains = { ... };
return ss::do_for_each(domains, [object = std::move(object)](const std::string &domain) {
return fetch(domain, object).then_wrapped([&domain](ss::future<std::string> &&fut) mutable {
if (!fut.failed()) {
std::cout << "fetch from domain: " << domain << " SUCCEEDED: " << fut.get0() << std::endl;
} else {
std::cerr << "fetch from domain: " << domain << " FAILED: " << fut.get_exception() << std::endl;
}
return ss::make_ready_future<>();
});
});
}这样就不需要使用 do_with
来维持循环变量;其中有两个注意点:
fetch 时失败了,也不应该返回 exception futureparallel_for_each在前一个 do_for_each
函数中,尽管每次循环执行的是异步操作,但是函数会保证在前一个异步操作完成后才会发起下一个异步操作(前面的
repeat、keep_doing
等函数也是如此),而有时候我们希望并发地发起异步操作,为此 Seastar 提供了
parallel_for_each 操作:
template <typename Iterator, typename Sentinel, typename Func>
SEASTAR_CONCEPT( requires (requires (Func f, Iterator i) { { f(*i) } -> std::same_as<future<>>; { i++ }; } && (std::same_as<Sentinel, Iterator> || std::sentinel_for<Sentinel, Iterator>)))
inline future<>
parallel_for_each(Iterator begin, Sentinel end, Func&& func) noexcept;
template <typename Range, typename Func>
SEASTAR_CONCEPT( requires requires (Func f, Range r) {
{ f(*std::begin(r)) } -> std::same_as<future<>>;
std::end(r);
} )
inline future<>
parallel_for_each(Range&& range, Func&& func) noexcept;和 do_for_each 几乎一致的签名(以及对 Func
的要求);但是需要注意的是,这里的 parallel
并不意味着这些异步操作会在其他 shard 运行,实际上他们还是在当前 shard
中,只不过不再限制「前一次异步操作完成后再发起下一次异步操作」
用 parallel_for_each 从 Google、Bing 和 Baidu
发起搜索并将其结果打印在标准输出:
void search(std::string &&object) {
static std::vector<std::string> domains = { ... };
return ss::parallel_for_each(domains, [object = std::move(object)](std::string &domain) {
return fetch(domain, object).then_wrapped([&domain](ss::future<std::string> &&fut) mutable {
if (!fut.failed()) {
std::cout << "fetch from domain: " << domain << " SUCCEEDED: " << fut.get0() << std::endl;
} else {
std::cout << "fetch from domain: " << domain << " FAILED: " << fut.get_exception() << std::endl;
}
return ss::make_ready_future<>();
}).then([]() { using namespace std::chrono_literals; return ss::sleep(1s).then([]() { std::cout << "sleep done\n"; }); });
});
}这里在 fetch
操作完成之后再往标准输出上输出一段话,从而帮助我们分辨各个操作的时序;编译运行:
% sudo ./a.outmax_concurrent_for_each如果我们在 parallel_for_each 代码示例的基础上还想控制最大并发度(即同时在执行的异步操作的数目),则可以使用
max_concurrent_for_each:
template <typename Iterator, typename Sentinel, typename Func>
SEASTAR_CONCEPT( requires (requires (Func f, Iterator i) { { f(*i) } -> std::same_as<future<>>; { i++ }; } && (std::same_as<Sentinel, Iterator> || std::sentinel_for<Sentinel, Iterator>) ) )
inline future<>
max_concurrent_for_each(Iterator begin, Sentinel end, size_t max_concurrent, Func&& func) noexcept;
template <typename Range, typename Func>
SEASTAR_CONCEPT( requires requires (Func f, Range r) {
{ f(*std::begin(r)) } -> std::same_as<future<>>;
std::end(r);
} )
inline
future<>
max_concurrent_for_each(Range&& range, size_t max_concurrent, Func&& func) noexcept;函数签名相比于 parallel_for_each 多了一个
max_concurrent 参数用于控制并发度。
在 parallel_for_each 代码示例的基础上控制最大并发度为
2(代码改动很少就不贴了):
% sudo ./a.out
fetch from domain: www.bing.com SUCCEEDED: content from bing
fetch from domain: www.google.com SUCCEEDED: content from google
sleep done
sleep done
fetch from domain: www.baidu.com FAILED: std::runtime_error("do not use Baidu please")
sleep done可以发现,对 Google 的 Bing 的搜索是并行的(完成的顺序也不确定),而对 Baidu 的搜索是在前两者完成之后才发起的,这也符合「最大并发度为 2」的语义。
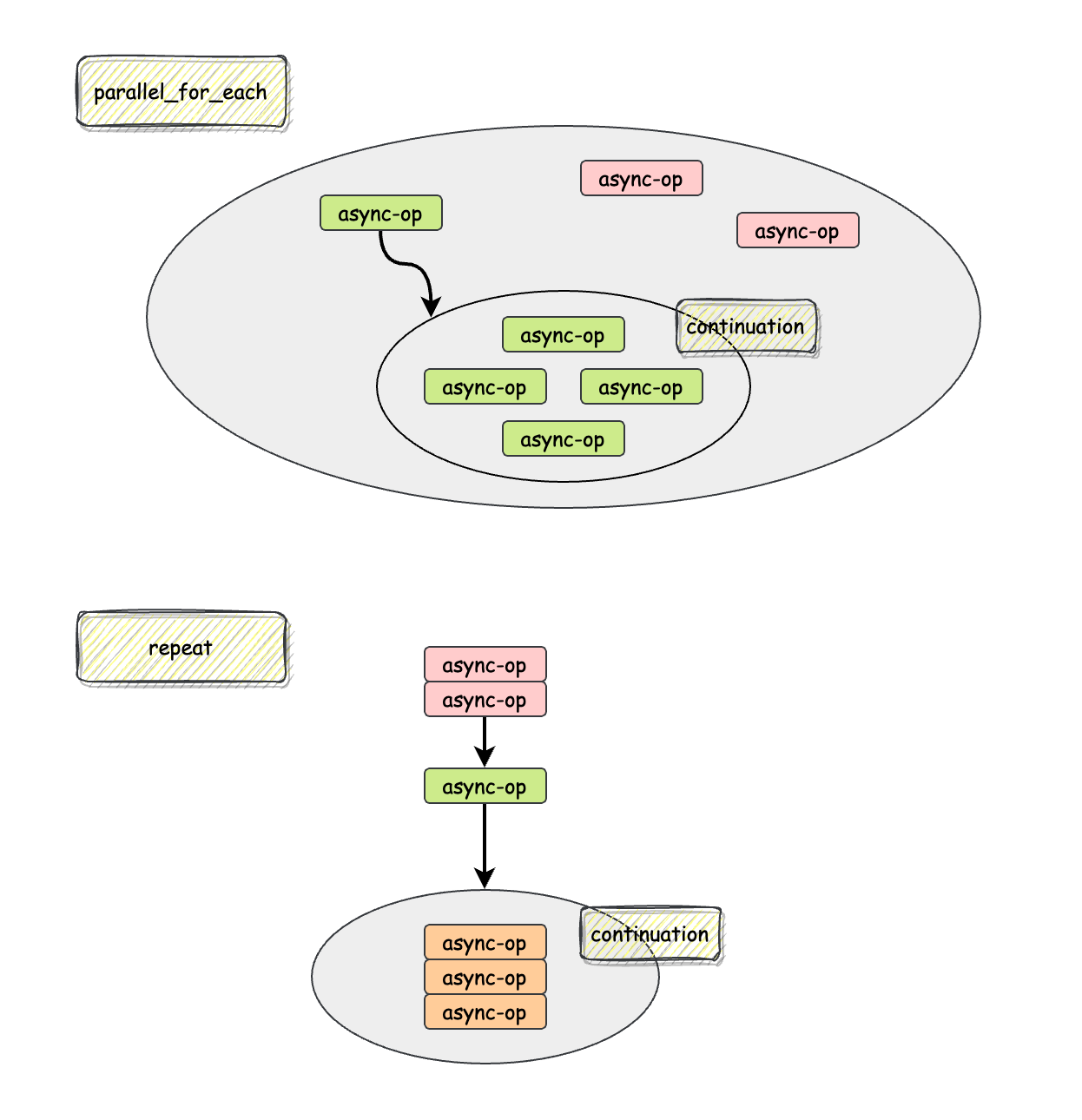
了解了这些 utility 的使用之后,我们可以来看看这些 utility 是如何实现的;这里从顺序循环和并行循环中各取出一个来探究其内部原理。
repeat对于顺序性循环,我们需要考虑两点:
第一个问题不同的 utility 都有不同的解决方法:repeat 和
repeat_until_value
通过异步操作的返回值进行判断,do_until
调用一个额外的函数作为判断结果…
对于第二点,我们很容易想到 continuation:异步操作结束后,其关联的 continuation 会被调度执行,这个顺序性恰好是我们需要的,所以我们只需要在执行了异步操作之后将剩余的循环执行逻辑封装成一个 continuation 和该异步操作绑定:
for (;;) {
// Do not type-erase here in case this is a short repeat()
auto f = futurator::invoke(action);
if (!f.available() || f.failed() || need_preempt()) {
return [&] () noexcept {
memory::scoped_critical_alloc_section _;
auto repeater = new internal::repeater<AsyncAction>(std::move(action));
auto ret = repeater->get_future();
internal::set_callback(f, repeater);
return ret;
}();
}
if (f.get0() == stop_iteration::yes) {
return make_ready_future<>();
}
}这里基本符合前面的逻辑,只是有一些不同:
need_preempt,如果是的话,即使异步操作返回的是一个 ready
future,我们也不会立刻重复该异步操作,而是封装成 continuation
并返回,从而让出 CPU,等待下一次 reactor 调度执行到该 continuationf.failed()),我们也并不直接返回,还是封装成
continuation(TODO: 这一点我没有想明白)需要注意的是,给一个已经 ready 的 future 设置 callback/continuation 也是 OK 的,此时 future 中的数据会被转移到 continuation 中去,并立即调度执行它:
template<typename T>
void future<T>::set_callback(continuation_base<T SEASTAR_ELLIPSIS>* callback) noexcept {
if (_state.available()) {
callback->set_state(get_available_state_ref());
::seastar::schedule(callback);
} else {
assert(_promise);
schedule(callback);
}
}repeater 是 continuation
的子类,不过我们只需要关系最重要的 run_and_dispose()
方法:
virtual void run_and_dispose() noexcept override {
if (_state.failed()) {
_promise.set_exception(std::move(_state).get_exception());
delete this;
return;
} else {
if (_state.get0() == stop_iteration::yes) {
_promise.set_value();
delete this;
return;
}
_state = {};
}
try {
do {
auto f = futurize_invoke(_action);
if (!f.available()) {
internal::set_callback(f, this);
return;
}
if (f.get0() == stop_iteration::yes) {
_promise.set_value();
delete this;
return;
}
} while (!need_preempt());
} catch (...) {
_promise.set_exception(std::current_exception());
delete this;
return;
}
_state.set(stop_iteration::no);
schedule(this);
} 首先检查前一次循环中异步操作的结果(执行了 continuation 的
run_and_dispose 方法就说明前一次循环的 future 已经 resolve
了),如果产生了异常就终止循环并返回该异常(通过 future
传播),如果没有异常而且异步操作返回
stop_iteration::yes,也需要终止循环。
检查完上一次异步操作的结果之后,开始执行下一次异步操作,这个过程和
repeat 函数中的无限循环类似,就不再赘述。
parallel_for_each前面看了 repeat
的实现,首先不直接看代码,先思考如果是自己写,大概思路是怎样?parallel_for_each
和 repeat
最大的不同就在于它没有「等上一次异步操作完成之后再发起下一次异步操作」,所以在实现上,最大的不同应该是发起异步操作的形式,以及异步操作激活
continuation 的形式。
因此首先还是要搞明白,在 parallel_for_each 中
continuation 的具体含义是什么;在
repeat、do_until 等需要保证顺序的 loop utility
中,continuation 的具体含义是「剩余的循环次数」,而在
parallel_for_each 这个不要求顺序执行的 loop utility 中(比如
parallel_for_each),continuation 的具体含义则是
「剩下的尚未 ready 的异步操作个数」;次数 和
个数的区别,就在于是否需要保持有序:
其中:
只有理解了二者的区别,我们才能明白 parallel_for_each
实现的要点:同时发起异步操作,但是在所有异步操作都 ready
之前,必须为至少一个尚未 ready 的异步操作设置
parall_for_each 的 continuation,该 continuation
会在异步操作 ready 后继续在当前剩余的尚未 ready 的异步操作中设置
continuation,直到所有异步操作都 ready
其代码如下:
template <typename Iterator, typename Sentinel, typename Func>
SEASTAR_CONCEPT( requires (requires (Func f, Iterator i) { { f(*i) } -> std::same_as<future<>>; { i++ }; } && (std::same_as<Sentinel, Iterator> || std::sentinel_for<Sentinel, Iterator>)))
inline future<>
parallel_for_each(Iterator begin, Sentinel end, Func&& func) noexcept {
parallel_for_each_state* s = nullptr;
while (begin != end) {
auto f = futurize_invoke(std::forward<Func>(func), *begin);
++begin;
memory::scoped_critical_alloc_section _;
if (!f.available() || f.failed()) {
if (!s) {
using itraits = std::iterator_traits<Iterator>;
size_t n{0U};
if constexpr (internal::has_iterator_category<Iterator>::value) {
// We need if-constexpr here because there exist iterators for which std::iterator_traits
// does not have 'iterator_category' as member type
n = (internal::iterator_range_estimate_vector_capacity(begin, end, typename itraits::iterator_category{}) + 1);
}
s = new parallel_for_each_state(n);
}
s->add_future(std::move(f));
}
}
// If any futures were not available, hand off to parallel_for_each_state::start().
// Otherwise we can return a result immediately.
if (s) {
// s->get_future() takes ownership of s (and chains it to one of the futures it contains)
// so this isn't a leak
return s->get_future();
}
return make_ready_future<>();
}这里依次对给定范围内的所有元素发起异步操作(不用「等前一次异步操作完成再发起下一个」),对于
unavailable 的 future,将其记录在 parallel_for_each_state
中——这又是 task 的一个子类,也是一个 continuation;对于已经
available 的 future,因为它只是一个
future<>,不带有值,所以我们可以直接忽略
由于 Seastar 中不鼓励忽略 future 中的异常,所以对于 available 但是
failed 的 future,我们把它当成 unavailable 的 future 一样对待:记录在
parallel_for_each_state 中等待处理
如果一轮下来发现所有异步操作返回的 future 都是 available 且 not
failed,我们直接返回一个 ready 的 future 表示本次 parallel
操作已经完成,否则的话返回一个尚未 ready 的 future——它必定是和
parallel_for_each_state 内部的 promise 关联
到这里或许会有疑问,如果有的异步操作调用不是马上 ready
的,那么如何在这些 future 被 resolve 之后激活
parallel_for_each_state 这个 continuation
做后续处理呢?以及有多个 unavailable future
时,应该由哪个谁来激活它呢?最终 parall_for_each
怎么保证所有异步操作都完成之后它自己才 resolve
呢?上面代码中我们并没有看到相关的处理。
其实这些逻辑在 get_future 中:
future<> parallel_for_each_state::get_future() {
auto ret = _result.get_future();
wait_for_one();
return ret;
}在返回内部的 promise 关联的 future
之前,首先将 unavailable future(关联的 promise) 和 continuation
关联起来以便后续激活它:
void parallel_for_each_state::wait_for_one() noexcept {
while (!_incomplete.empty() && _incomplete.back().available()) {
if (_incomplete.back().failed()) {
_ex = _incomplete.back().get_exception();
}
_incomplete.pop_back();
}
// If there's an incomplete future, wait for it.
if (!_incomplete.empty()) {
internal::set_callback(_incomplete.back(), static_cast<continuation_base<>*>(this));
// This future's state will be collected in run_and_dispose(), so we can drop it.
_incomplete.pop_back();
return;
}
// Everything completed, report a result.
if (__builtin_expect(bool(_ex), false)) {
_result.set_exception(std::move(_ex));
} else {
_result.set_value();
}
delete this;
}从函数的名字可以大致猜出它做了什么:等待一个尚未完成的异步操作,而事实上他也是这样做的;这里从后往前遍历所有
future,找到第一个 unavailable 的 future,并将当前
parallel_for_each_state 作为它的
continuation,对于期间的所有 available future,如果
failed,则记录下其异常值(调用了 get_exception 之后 Seastar
就不会抱怨没有处理异常了),否则直接忽略
如果找到了这样一个 unavailable future,那么将其和
parallel_for_each_state 关联。
要注意异常处理,如果发起的异步操作返回了异常,那么我们应该要向用户报告该异常,然而
parallel_for_each 返回的是一个
future<>,最多只能携带一个
exception,而可能有多次异步操作返回了异常,Seastar
的做法是随机返回其中一个,_ex
字段记录着异步操作返回的异常,这个字段可能会被多次赋值
在这个 continuation 的 run_and_dispose
方法中,我们记录下该异步操作的异常值(如果有的话),然后再通过
wait_for_one 选择其中尚未 ready 的 future
继续关联,直到所有的异步操作都完成:
void parallel_for_each_state::run_and_dispose() noexcept {
if (_state.failed()) {
_ex = std::move(_state).get_exception();
}
_state = {};
wait_for_one();
}所以 parallel_for_each_state 这个 continuation
其实只是在不停地等待异步操作完成(以及处理它们可能产生的异常),到这里我们可以解答前面说的三个问题:
parallel_for_each_stateparallel_for_each_state 关联,直到所有 future 都
resolve,才 resolve parallel_for_each 返回的 future