2022-03-05
最近在为 Lua/JS 子请求实现 HTTP 连接池,池子的大小是固定的,但是创建的连接数是由跑在我们 web server 之上的用户代码(Lua/JS)决定的,所以在空间不够时必然需要淘汰旧的连接。很容易想到 LRU 淘汰算法,通常我们使用哈希表+双向链表实现1:哈希表用于存储数据,并且支持 \(\mathcal{O}(1)\) 查找;而双向链表用于维护元素的访问时序,并且可以\(\mathcal{O}(1)\) 删除。
现在我已经有了哈希表,只是缺一个双向链表记录元素的访问时序。很容易想到
STL 中的
std::list,这是最常见的选择,但最终我没有用它,而是选择了
boost::intrusive::list。
std::list(以及标准库中的其他容器)是非侵入式的,而
boost::intrusive::list
则是一种侵入式容器。所谓侵入式和非侵入式,其实指的是容器是否入侵了对容器所容纳的元素类型。
对于 std::list,其节点和原始对象的关系如下:
|--------------|
| next |
| prev |
| |--------| |
| | OBJECT | |
| |--------| |
|--------------|可以看到,链表节点其实是对原始对象的一层包裹,并加上了前后指针;每次插入一个对象分配节点时时,都需要将原始对象拷贝进去。
如果原始对象很大,或者它不支持拷贝,那么怎么办呢?此时可以考虑让链表存储对象的指针(比如
std::list<T*>),但是这仍免不了额外的内存分配以及数据拷贝(此时有一个指针的拷贝,以及三个指针大小的内存分配,使用智能指针的话则更多,并且还会影响引用计数)。
而对于
boost::intrusive::list,其节点和原始对象的关系如下:
|--------------|
| OBJECT |
|--------------|对象即节点,节点即对象;也就是说侵入式容器直接将对象本身作为链表节点,所以并不会产生额外的内存分配以及数据拷贝;而链表之所以是链表,是因为元素存在着指向其他元素的链接,所以直接使用原始对象作为链表节点的话,就需要对象中本身就包含指向其他元素的指针,这是使用侵入式容器的前提(precondition),所以对象在设计的时候就需要将其考虑进去,所以说它是侵入式的。
倘若元素只存储在一个容器中,那么二者的效率并没有区别:都需要为对象和前后指针分配内存,无非是原始对象由容器还是对象本身来分配的问题,而且
std::list
会替用户管理对象的生命周期,使用起来还会更加方便。但是在 LRU
的情况下,对象需要出现在两个容器中,这个时候侵入式容器的价值就体现出来了。
做一下总结2:
std::list):由链表来管理对象的生命周期,且不需要用户维护前后指针,但是缺点在于它需要进行额外的内存分配以及数据拷贝。boost::intrusive::list):需要用户自己在对象中加上前后指针,对象的生命周期由用户自己管理,但是不需要额外的内存分配以及数据拷贝。侵入式容器在平常的业务开发中使用的比较少,但是在许多框架中则使用得非常广泛,比如
Linux 内核中的 struct list_head,Nginx 中的
ngx_queue_t 和 ngx_rbtree_t…
Boost 在 boost::intrusive
命名空间/库下提供了许多侵入式容器,对于这些侵入式容器,Boost 是这样3解释的:
Boost.Intrusive is a library presenting some intrusive containers to the world of C++. Intrusive containers are special containers that offer better performance and exception safety guarantees than non-intrusive containers (like STL containers).
The performance benefits of intrusive containers makes them ideal as a building block to efficiently construct complex containers like multi-index containers or to design high performance code like memory allocation algorithms.
While intrusive containers were and are widely used in C, they became more and more forgotten in C++ due to the presence of the standard containers which don’t support intrusive techniques.Boost.Intrusive wants to push intrusive containers usage encapsulating the implementation in STL-like interfaces. Hence anyone familiar with standard containers can easily use Boost.Intrusive.
这段话提到了三点:
intrusive::listBoost.Intrusive 中提供了许多侵入式容器4:
slist:单向链表,给用户类型带来的空间开销只有一个指针大小,但是许多操作的时间复杂度是
\(\mathcal{O}(n)\),所以需要谨慎使用list:和 std::list
类似的双向链表,给用户类型带来的空间开销只有两个指针大小,许多操作的时间复杂度为
\(\mathcal{O}(1)\),是最常用的侵入式容器set/multiset/rbtree:和
std::set/std::multiset
类似的关联容器,基于红黑树;给用户类型带来的空间开销为三个指针,许多操作的时间复杂度为
\(\mathcal{O}(\log{}n)\)avl_set/avl_multiset/avltree:和
std::set/sed::multiset 类似的关联容器,基于
AVL 树;给用户类型带来的空间开销为三个指针,许多操作的时间复杂度为 \(\mathcal{O}(\log{}n)\)splay_set/splay_multiset/splaytree:和
std::set/sed::multiset
类似的关联容器,基于伸展树;给用户类型带来的空间开销为三个指针;伸展树没有
\(\mathcal{O}(1)\)
时间复杂度的操作,但是缓存局部性会更好一些,许多操作的时间复杂度为 \(\mathcal{O}(\log{}n)\)sg_set/sg_multiset/sgtree:和
std::set/sed::multiset 类似的关联容器,基于
scapegoat
tree;这种树可以配置所需的平衡因子,以实现所需的再平衡频率和搜索时间折衷;它给用户类型带来的空间开销为三个指针,许多操作的时间复杂度为
\(\mathcal{O}(\log{}n)\)这里主要介绍常用的 list
每个要插入到侵入式容器中的类都需要包含一个 hook,该 hook 将提供可插入容器中的必要数据和资源(比如前后指针),Boost.Intrusive 提供了三种 hook:
所谓 bask hooks,就是一个含有必要数据和资源的基类,原始对象通过继承该基类从而获得这些数据与资源:
#include <boost/intrusive/list.hpp>
struct Record : public boost::intrusive::list_base_hook<> {
public:
explicit Record(std::string name) : name(std::move(name)) {}
std::string name;
};
Record cr1("tom");
Record cr2("jerry");
Record cr3("spike");
boost::intrusive::list<Record> rlst;
rlst.push_back(cr1);
rlst.push_front(cr2);
rlst.push_back(cr3);
std::cout << "size: " << rlst.size() << std::endl;注意到 list_base_hook 是一个模板类:
template <class ...Options>
class list_base_hook;可以指定一些模板参数(都有默认值):
tag<class Tag>:这个用于给 hook
指定一个 tag,这样一个对象可以放在多个侵入式容器中,而不同容器使用的
hook 可以通过这个 tag 区分link_mode<link_mode_type LinkMode>:这个用于指定链表的链接策略,目前
link_mode_type 为
normal_link、safe_link(默认) 以及
auto_unlinkvoid_pointer<class VoidPointer>:这个用于指定节点之间链接的指针类型,默认情况下用的是
void *,但是我们也可以使用诸如智能指针等指针类型,比如
void_pointer<my_smart_pointer<void>>此外,在创建侵入式链表时:
template <class T, class ...Options>
class list;除了容器中的元素类型是必填之外,还有一些可选的模板参数可以指定:
base_hook<class Hook>/member_hook<class T, class Hook, Hook T::* PtrToMember>/value_traits<class ValueTraits>:,此处有三种类型参数可以指定,但是在使用
base hook 时,我们只关心第一种;如果在使用 list_base_hook
时没有使用默认的类型,那么此处就得进行指定,此处的 Hook
即继承的 list_base_hook 的类型constant_size_time<bool Enabled>:boost::inrusive::list
有一个 size() 方法,这个选项用于指定 size()
方法是否必须为常量时间的复杂度,如果是的话,则会在容器内部记录下当前容器中的元素数目(默认情况),否则需要实时计算size_type<class SizeType>:用于指定该容器的
size() 方法的返回值,默认情况下是
std::size_t,绝大部分情况下不用改这个参数有时候继承并不是一个最好的选择,因为类层级的增加势必会带来一定的消耗,而且可能会影响原有的类层级设计;因此Boost.Intrusive
还提供了 member hook
的方式来将容器所需要的数据插入到对象当中,简而言之就是显式地在对象类中插入一个
list_member_hook 作为公共数据成员,这种做法会更贴近传统 C
侵入式容器的做法。
struct Record {
public:
explicit Record(std::string name) : name(std::move(name)) {}
std::string name;
boost::intrusive::list_member_hook<> hook;
};正如为使用 list_base_hook 的对象创建侵入式链表时需要使用
base_hook 作为 boost::intrusive::list
的第二个模板参数一样,为使用 list_member_hook
的对象创建侵入式链表时则需要使用 member_hook
作为链表的第二个模板参数:
using namespace boost::intrusive;
list<Record, member_hook<Record, list_member_hook<>, &Record::hook>> rlst;member_hook 的类型定义如下:
template< typename Parent
, typename MemberHook
, MemberHook Parent::* PtrToMember>
struct member_hook;list_member_hook 所属的类型作为其第一个模板参数list_member_hook
成员的类型作为其第二个模板参数list_member_hook
成员的指针作为其第三个模板参数后续的其他元素操作就和 base hook 一样,就不赘述了
std::list 为删除元素提供了三种方法:
pop_front()/pop_back()remove()erase()其中 pop_front()/pop_back()
方法只能删除特定位置(首尾)的对象,而不能删除指定位置的对象;erase()
方法虽然可以删除指定位置的对象,但是它只接受一个迭代器,而不接受原始对象;remove()
方法虽然接受原始对象,但是它会删除链表中所有和该对象相等的元素。
那倘若我们拿到了一个对象,并向将其从链表中删除,怎么办呢?我们通常会在对象中保存它在
std::list 中所处位置的迭代器,删除时就可以使用
erase() 方法,但是这种情况下原始元素有得保存一个
std::list<T>
的迭代器(这是不是也算是侵入了?)。或者我们可以通过原始对象计算出它在
std::list 中的迭代器,这个方法我还没有试过。
std::list
无法处理这个问题,因为对象本身并不包含链表所需要的前后指针,所以通过裸的对象(而不是迭代器)来将其从链表中删除,首先得通过它找到链表节点以及前后指针;找到链表节点后如何判断该节点中包含的对象和要删除的对象就是同一个呢?除非链表中保存的是对象的指针,否则只能靠对象本身实现的
operator == 来找到所有与之相等的元素;而在
boost::intrusive 中则没有这个烦恼,std::list
中有的三种删除方法它都有,其签名和含义也是一样的;但是对于前面提到的删除指定元素的场景,我们无需在元素中保存一个迭代器,因为对象中已经包含了链接信息。介绍文档5中提到了 Boost
中的侵入式容器很重要的一个优点:
The computation of an iterator to an element from a pointer or reference to that element is a constant time operation (computing the position of T* in a std::list<T*> has linear complexity).
也就是说,在 Boost 侵入式容器中,我们可以很容易地从一个原始对象(或者其指针)获取到它在该容器中的迭代器,从而可以很方便地进行删除:
Record cr1("tom");
Record cr2("jerry");
Record cr3("spike");
boost::intrusive<Record> rlst;
rlst.push_back(cr1);
rlst.push_back(cr2);
rlst.push_back(cr3);
rlst.erase(rlst.iterator_to(cr2));Boost.Intrusive 提供了 iterator_to6
用于从一个对象获取到该对象在容器中的迭代器,并且它的时间复杂度是 \(\mathcal{O}(1)\) 的。
使用 Boost
侵入式容器时,非常重要的一点就是需要注意元素和容器的释放顺序。前面提到过,侵入式容器中的节点就是对象本身,而不像
std::list
一样包含对象的拷贝,而且侵入式容器也不负责管理对象的生命周期,那么:
比如下面这个例子:
Record rc1("tom");
Record rc2("jerry");
boost::intrusive::list<Record> list;
list.push_back(rc1);
list.push_back(rc2);
Record rc3("spike");
list.push_back(rc3);rc3 在 list 之后被创建,根据 C++
变量的析构规则,后创建的变量先被析构,所以 rc3 会在
list 之前被析构,此时由于默认使用的是
auto_link,所以运行会产生一个断言失败:
% ./a.out
Assertion failed: (!hook.is_linked()), function destructor_impl, file generic_hook.hpp, line 48.
[1] 52645 abort ./a.out查看源码发现:
template<class Hook>
BOOST_INTRUSIVE_FORCEINLINE void destructor_impl(Hook &hook, detail::link_dispatch<safe_link>)
{ //If this assertion raises, you might have destroyed an object
//while it was still inserted in a container that is alive.
//If so, remove the object from the container before destroying it.
(void)hook; BOOST_INTRUSIVE_SAFE_HOOK_DESTRUCTOR_ASSERT(!hook.is_linked());
}也就是说,我们析构了一个还在链表中的对象,并且 Boost 建议我们在析构它之前先将其从链表中删除。
针对前面的问题,是否有一种办法可以让对象释放时自动从链表中摘除呢?Boost.Intrusive
的确提供了这样的机制,就是前面提到的
link_mode,链表的链接策略。默认使用的是
safe_link,这种策略有以下性质:
其中第二点就是前面碰到的问题的原因,而第三点则会导致容器中不能插入重复对象:
Record rc1("tom");
boost::intrusive::list<Record> rlst;
rlst.push_back(rc1);
rlst.push_back(rc2);编译运行:
Assertion failed: (!safemode_or_autounlink || node_algorithms::inited(to_insert)), function push_back, file list.hpp, line 273.
[1] 82647 abort ./a.out回到前面的问题,我们可以使用 auto_unlink 链接策略,它有
safe_link 没有的两个特性:
unlink
方法,用户可通过该方法随时随地地将其从容器中手动摘除需要注意,不管是自动还是通过 unlink
方法手动从容器中摘除,我们都不持有该容器的引用,这样带来了一个使用限制:不能在具有
\(\mathcal{O}(1)\) 时间复杂度
size() 方法的容器中使用,因为:
auto_unlink 类型的 hook
内部并不会持有对所在容器的引用size() 方法具有 \(\mathcal{O}(1)\)
时间复杂度,是因为容器中存储了其保存的元素个数;而
auto_unlink
将元素从容器中摘除时,并不持有容器的引用,也就无法更新容器中的数据using namespace boost::intrusive;
struct Record : public list_base_hook<link_mode<auto_link>> {
...
};
list<Record, base_hook<list_base_hook<link_mode<auto_unlink>>>, constant_time_size<false>> rlst;
{
Record rc1("tom");
Record rc2("jerry");
rlst.push_back(rc1);
rlst.push_back(rc2);
std::cout << rlst.size() << std::endl; // 2
}
std::cout << rlst.size() << std::endl; // 0
{
Record rc1("tom");
Record rc2("jerry");
rlst.push_back(rc1);
rlst.push_back(rc2);
rc1.unlink();
rc2.unlink();
std::cout << rlst.size() << std::endl; // 0
}
std::cout << rlst.size() << std::endl; // 0此外,auto_unlink hook 也有 safe_link
的一些性质(1, 3, 4):
当要存储的对象可能具有不同或未知的大小时,也可以使用侵入式容器。这允许将基础对象和派生对象存储在同一个容器中,比如下面这个例子7:
class Window : public list_base_hook<> {
public:
typedef list<Window> win_list;
static win_list all_windows;
Window() { all_windows.push_back(*this); }
virtual ~Window() { all_windows.erase(win_list::s_iterator_to(*this)); }
virtual void Paint() = 0;
};
Window::win_list Window::all_windows;
class FrameWindow : public Window { void Paint() { /* */ } };
class EditWindow : public Window { void Paint() { /* */ } };
class CanvasWindow : public Window { void Paint() { /* */ } };
void paint_all_windows() {
for(Window::win_list::iterator i(Window::all_windows.begin())
, e(Window::all_windows.end())
; i != e; ++i) {
i->Paint();
}
}
class MainWindow : public Window {
FrameWindow frame_;
EditWindow edit_;
CanvasWindow canvas_;
public:
void Paint(){ /* */ }
};
int main() {
MainWindow window;
paint_all_windows();
return 0;
}在上面这个例子中,每创建一个
Window(或者其子类)对象,就会将该对象挂在全局的
all_windows 链表的尾部;每释放一个
Window(或者其子类)对象,就将其从该全局链表中删除。对于标准库容器(比如
std::list),我们需要在其中存储对象的指针或者引用,才能在同一容器中同时存储基类和子类对象,但是在
Boost 侵入式容器中,直接存储对象也可以实现这个功能。
可以看到,Boost.Intrusive 的确有着许多优点,但是相比于
std::list,使用起来还是比较麻烦,而且真正用的时候不少东西需要注意;那么什么时候应该使用这些侵入式容器呢,Boost
官方给了我们一些建议8:
侵入式容器一般用于高度优化的算法,在这些算法中速度是一个关键问题并且:
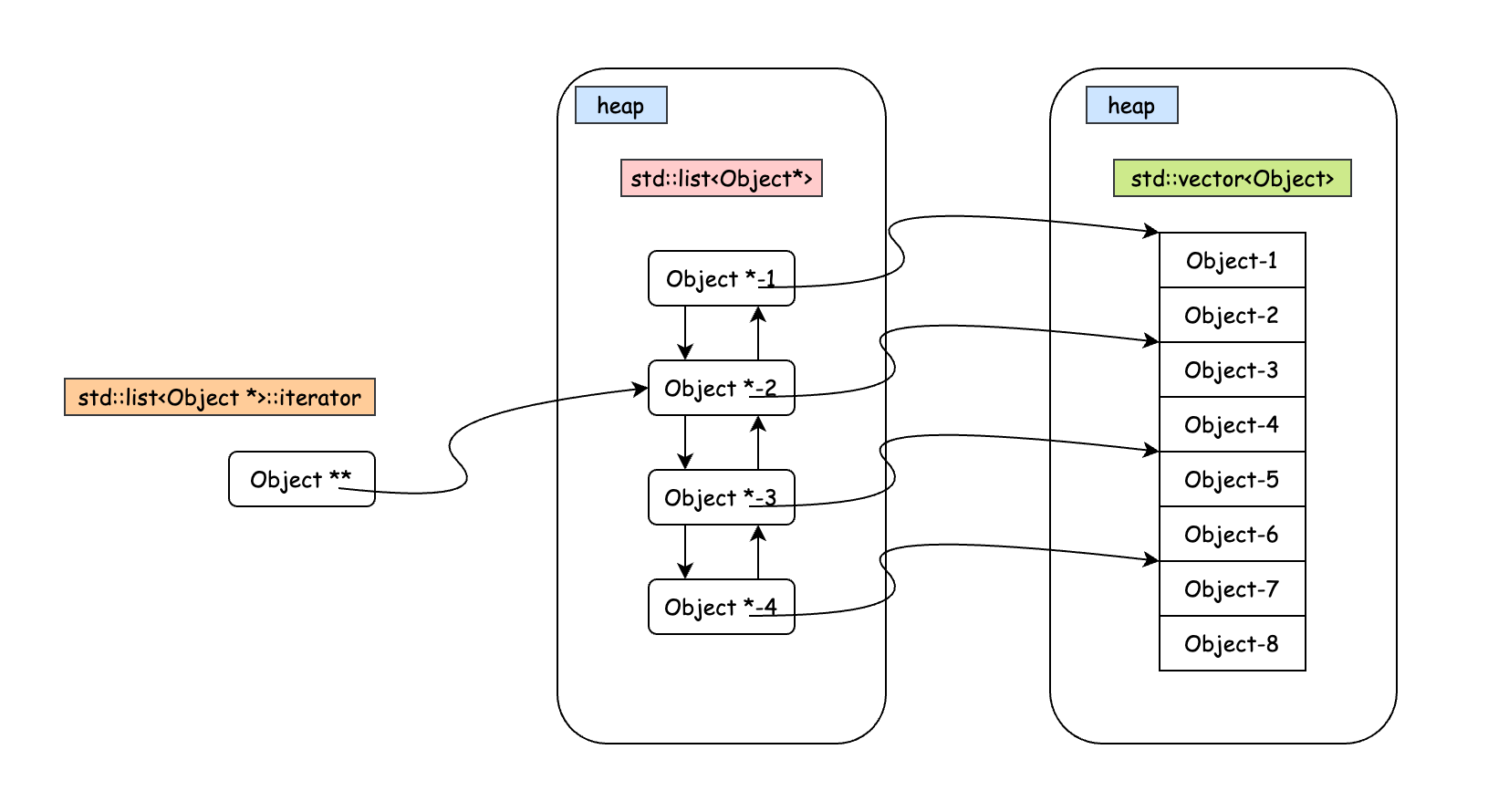
iterator_to)最后一点在元素需要被放置在多个容器的情况下就显得很重要了:比如有一个
std::vector<Object>,并且还有一个存储这些对象子集
std::list<Object *>(这里使用指针而不是对象,否则和
vector
里面的对象就是两份不同的对象了),则链表中的迭代器(std::list<Object *>::iterator)操作对象则需要两步操作:
std::vector 中的对象(deference
pointer)这种情况下,尽管对象是存储在具有连续内存的 std::vector
中,但是 std::list<Object *>
链表的节点可能分散在堆内存中,所以极有可能造成 cache miss(deference 一个
iterator 拿到的是链表节点,CPU 自动将该堆中该 iterator 附近的内容加载至
cache,由于链表节点并不连续存储,所以加载到内存的内容很有可能后续用不上,也就造成了
cache miss)
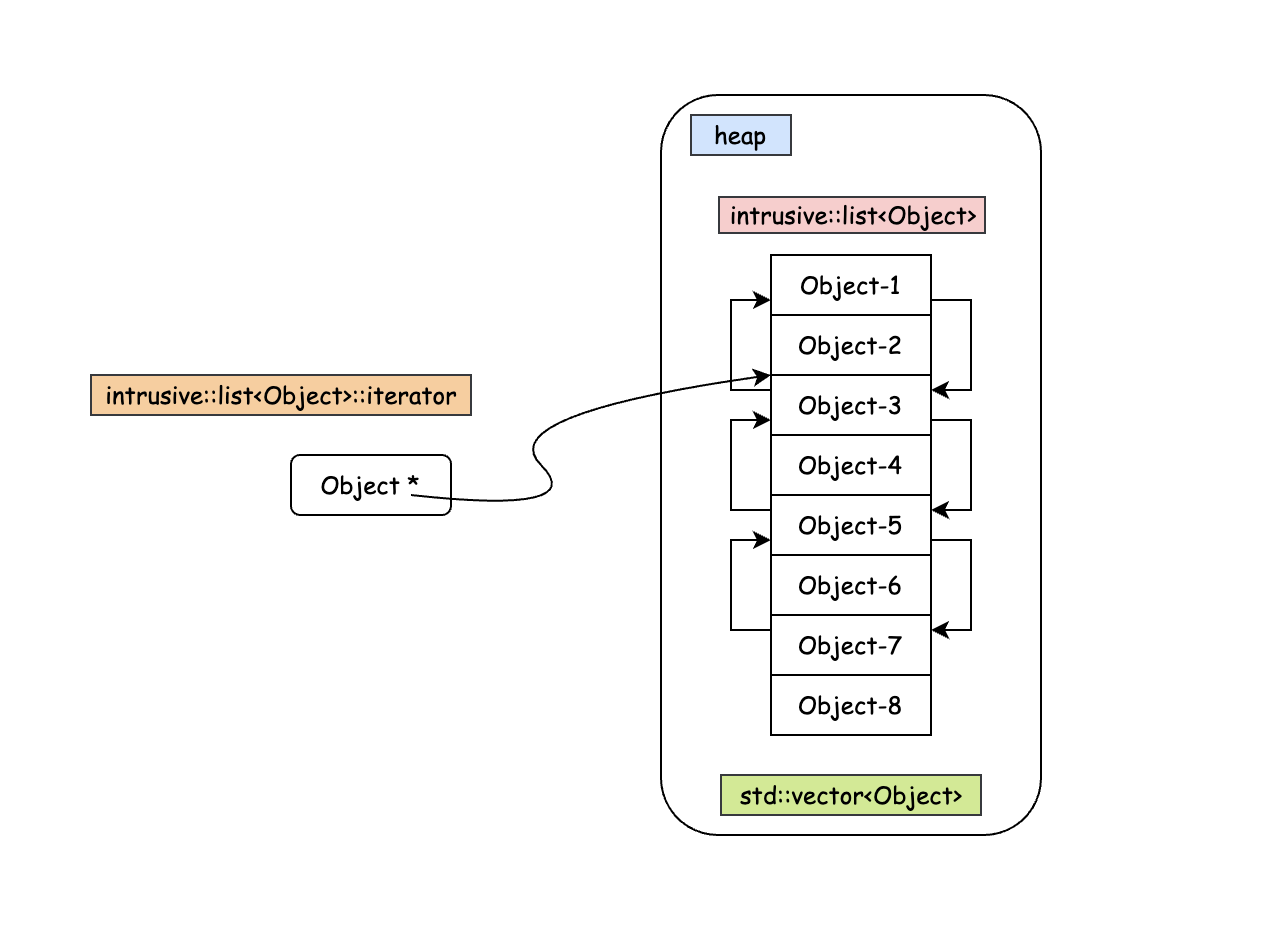
而使用 boost::intrusive::list 则没有这个问题,
因为链表节点就是对象(在 std::vector 中),所以 deference 该
iterator 拿到的就是对象本身,此时 CPU 会将其附近的内容加载至
cache,而对象处于线性的 std::vector
中,所以对象附近很有可能是其他对象,后续的操作就很可能 cache hit 了
总之,Boost 侵入式容器需要小心谨慎使用,非必要场合不使用;但是必要场合,我觉得我们应该尽可能地用,毕竟编程能力就是在刀尖上行走时才能得到大幅的提升。
https://stackoverflow.com/questions/2504178/lru-cache-design↩︎
https://www.boost.org/doc/libs/1_78_0/doc/html/intrusive/intrusive_vs_nontrusive.html↩︎
https://www.boost.org/doc/libs/1_78_0/doc/html/intrusive.html#intrusive.introduction.introduction_presenting↩︎
https://www.boost.org/doc/libs/1_78_0/doc/html/intrusive/presenting_containers.html↩︎
https://www.boost.org/doc/libs/1_78_0/doc/html/intrusive.html#intrusive.introduction.introduction_presenting↩︎
https://www.boost.org/doc/libs/1_78_0/doc/html/intrusive/obtaining_iterators_from_values.html↩︎
https://www.boost.org/doc/libs/1_78_0/doc/html/intrusive/usage_when.html↩︎
https://www.boost.org/doc/libs/1_78_0/doc/html/intrusive/usage_when.html↩︎